Der Kurs gliedert sich thematisch in drei Breiche, die die Teilnehmer schrittweise an Apache Spark heranführen.
Der erste (eher theoretische) Teil gibt einen knappen Überblick aktueller Technologien zur Speicherung und Verarbeitung großer Datenmengen (Hadoop und Kubernetes), und welchen Platz Spark als wichtiges Datenverarbeitungsframework darin einnimmt.
Der zweite, praktisch angelegte Teil umfasst eine ausführliche Einführung in die Arbeit mit Apache Spark mit Python (PySpark). Dieses Modul stellt den Kern des Workshops dar. Dementsprechend werden dabei alle wichtigen Punkte angesprochen:
• Einladen von Daten
• Datenaufbereitung (Transformation, Filtern, Joinen, Aggregation)
• Anbindung verschiedener Datenquellen
• Ausführungsmodelle von Apache Spark
• Integration von dem Python Data Science Module Pandas und wichtige Unterschiede
Die Teilnehmer werden all diese Schritte direkt an praktischen Beispielen und Übungen umsetzen. Zusätzlich werden auch gängige Grundkonzepte zur Datenorganisation in Big Data Projekten angesprochen.
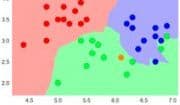
Der dritte Teil behandelt schließlich die in Spark vorhandenen Möglichkeiten zur Datenanalyse und zum maschinellen Lernen (ML). Es werden kurz die grundlegenden Konzepte und Vorgehensweisen von ML erläutert und an einem Beispiel mit PySpark praktisch angewandt.
Der Kurs gliedert sich thematisch in drei Breiche, die die Teilnehmer schrittweise an Apache Spark heranführen.
Der erste (eher theoretische) Teil gibt einen knappen Überblick aktueller Technologien zur Speicherung und Verarbeitung großer Datenmengen (Hadoop und Kubernetes), und welchen Platz Spark als wichtiges Datenverarbeitungsframework darin einnimmt.
Der zweite, praktisch angelegte Teil umfasst eine ausführliche Einführung in die Arbeit mit Apache Spark mit Python (PySpark). Dieses Modul stellt den Kern des Workshops dar. Dementsprechend werden dabei alle wichtigen Punkte angesprochen:
• Einladen von Daten
• Datenaufbereitung (Transformation, Filtern, Joinen, Aggregation)
• Anbindung verschiedener Datenquellen
• Ausführungsmodelle von Apache Spark
• Integration von dem Python Data Science Module Pandas und wichtige Unterschiede
Die Teilnehmer werden all diese Schritte direkt an praktischen Beispielen und Übungen umsetzen. Zusätzlich werden auch gängige Grundkonzepte zur Datenorganisation in Big Data Projekten angesprochen.
Der dritte Teil behandelt schließlich die in Spark vorhandenen Möglichkeiten zur Datenanalyse und zum maschinellen Lernen (ML). Es werden kurz die grundlegenden Konzepte und Vorgehensweisen von ML erläutert und an einem Beispiel mit PySpark praktisch angewandt.


































{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}