Sie erhalten einen Überblick über die im Data Science, Data Mining, Machine Learning und Deep Learning populäre Programmiersprache Python. Wir verwenden die Anaconda Distribution (nach eigenen Angaben “The World’s most popular data science platform“) und als Entwicklungsumgebung/IDE wird spyder verwendet.
Nach dieser einwöchigen Weiterbildung zum data scientist, welche die Grundlagen von Data Engineering und Data Mining beinhaltet, können Sie Daten aus verschiedenen Formaten und von Datenbanken (mit den Paketen SQLAlchemy und pandas) einlesen, Daten mit seaborn / matplotlib plotten bzw. Daten mit pandas bereinigen (fehlende Werte ersetzen, Zeilen und Spalten anpassen, neue Spalten erzeugen) und Berechnungen mit numpy durchführen.
Sie kennen die wichtigsten Datentypen in Python, können eigene einfache Funktionen schreiben und kennen die Umsetzung von Control Flows (For-Schleife, If-Else). Nach Absolvierung des Data Scientist Kurs verstehen Sie das Grundkonzept eines pandas DataFrames und können damit Data Wrangling und Data Cleaning durchführen. Die Vorverarbeitung von Daten (data preprocessing) für die Umsetzung von Algorithmen mit scikit-learn wird angesprochen.
Die Einteilung von Machine Learning in supervised-unsupervised (überwachtes-unüberwachtes Lernen) und Reinforcement Learning ist Ihnen bekannt und Sie können mit scikit-learn eigenständig Algorithmen in Python trainieren, validieren, einen Train-Test Datensplit durchführen und Gütekriterien zur Beurteilung eines Algorithmus berechnen und interpretieren.
Sie wissen, was Overfitting (Überanpassung) bedeutet, wie dies nach dem Training eines Algorithmus identifiziert werden kann und welche Anpassungen es bei einzelnen Algorithmen gibt, um Overfitting zu verringern.
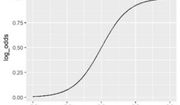
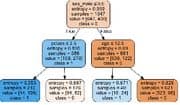
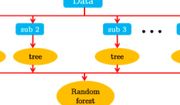
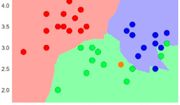
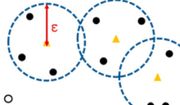
Ein großer Schwerpunkt im Kurs liegt auf der Weiterbildung im Machine Learning, wofür scikit-learn benutzt wird. Die Umsetzung und das intuitive Verständnis der bekannten Algorithmen des Maschinellen Lernens ist im Fokus. Die Fortbildung umfasst Algorithmen für die Regression (Lineare Regression, Random Forest, Neural Network, Decision Tree), für die Klassifikation (Logistische Regression, Enscheidungsbaum, Random Forest, AdaBoost, K-Nearest Neighbor) und dem Clustering (K-Means, DBSCAN). Desweiteren wird das Erstellen eines Ensembles erläutert und die Konzepte von Grid-Search zur automatischen Optimierung von Hyperparametern und die Umsetzung einer Kreuzvalidierung (Cross-Validation) an Stelle eines klassischen Train-Test-Datensplits.
Am Ende der fünftägigen Data Science Weiterbildung ist die Einstiegshürde für die Benutzung von Python für Machine Learning, Data Science, Data Mining, Business Intelligence bzw. Data Analytics genommen und erweiterte Grundlagen in scikit-learn gelernt, so dass Sie eigenständig Ihr Wissen nach dem Seminar Stück für Stück erweitern können. Der Schwerpunkt während des Seminars liegt auf der selbstständigen Umsetzung auf Ihrem Laptop mit aktiver Unterstützung des Dozenten, so dass sie viel Praxiswissen als angehender Data Scientist lernen können.
Sie erhalten einen Überblick über die im Data Science, Data Mining, Machine Learning und Deep Learning populäre Programmiersprache Python. Wir verwenden die Anaconda Distribution (nach eigenen Angaben “The World’s most popular data science platform“) und als Entwicklungsumgebung/IDE wird spyder verwendet.
Nach dieser einwöchigen Weiterbildung zum data scientist, welche die Grundlagen von Data Engineering und Data Mining beinhaltet, können Sie Daten aus verschiedenen Formaten und von Datenbanken (mit den Paketen SQLAlchemy und pandas) einlesen, Daten mit seaborn / matplotlib plotten bzw. Daten mit pandas bereinigen (fehlende Werte ersetzen, Zeilen und Spalten anpassen, neue Spalten erzeugen) und Berechnungen mit numpy durchführen.
Sie kennen die wichtigsten Datentypen in Python, können eigene einfache Funktionen schreiben und kennen die Umsetzung von Control Flows (For-Schleife, If-Else). Nach Absolvierung des Data Scientist Kurs verstehen Sie das Grundkonzept eines pandas DataFrames und können damit Data Wrangling und Data Cleaning durchführen. Die Vorverarbeitung von Daten (data preprocessing) für die Umsetzung von Algorithmen mit scikit-learn wird angesprochen.
Die Einteilung von Machine Learning in supervised-unsupervised (überwachtes-unüberwachtes Lernen) und Reinforcement Learning ist Ihnen bekannt und Sie können mit scikit-learn eigenständig Algorithmen in Python trainieren, validieren, einen Train-Test Datensplit durchführen und Gütekriterien zur Beurteilung eines Algorithmus berechnen und interpretieren.
Sie wissen, was Overfitting (Überanpassung) bedeutet, wie dies nach dem Training eines Algorithmus identifiziert werden kann und welche Anpassungen es bei einzelnen Algorithmen gibt, um Overfitting zu verringern.
Ein großer Schwerpunkt im Kurs liegt auf der Weiterbildung im Machine Learning, wofür scikit-learn benutzt wird. Die Umsetzung und das intuitive Verständnis der bekannten Algorithmen des Maschinellen Lernens ist im Fokus. Die Fortbildung umfasst Algorithmen für die Regression (Lineare Regression, Random Forest, Neural Network, Decision Tree), für die Klassifikation (Logistische Regression, Enscheidungsbaum, Random Forest, AdaBoost, K-Nearest Neighbor) und dem Clustering (K-Means, DBSCAN). Desweiteren wird das Erstellen eines Ensembles erläutert und die Konzepte von Grid-Search zur automatischen Optimierung von Hyperparametern und die Umsetzung einer Kreuzvalidierung (Cross-Validation) an Stelle eines klassischen Train-Test-Datensplits.
Am Ende der fünftägigen Data Science Weiterbildung ist die Einstiegshürde für die Benutzung von Python für Machine Learning, Data Science, Data Mining, Business Intelligence bzw. Data Analytics genommen und erweiterte Grundlagen in scikit-learn gelernt, so dass Sie eigenständig Ihr Wissen nach dem Seminar Stück für Stück erweitern können. Der Schwerpunkt während des Seminars liegt auf der selbstständigen Umsetzung auf Ihrem Laptop mit aktiver Unterstützung des Dozenten, so dass sie viel Praxiswissen als angehender Data Scientist lernen können.







































{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}